If AI alignment is only as hard as building the steam engine, then we likely still die
You may have seen this graph from Chris Olah illustrating a range of views on the difficulty of aligning superintelligent AI:
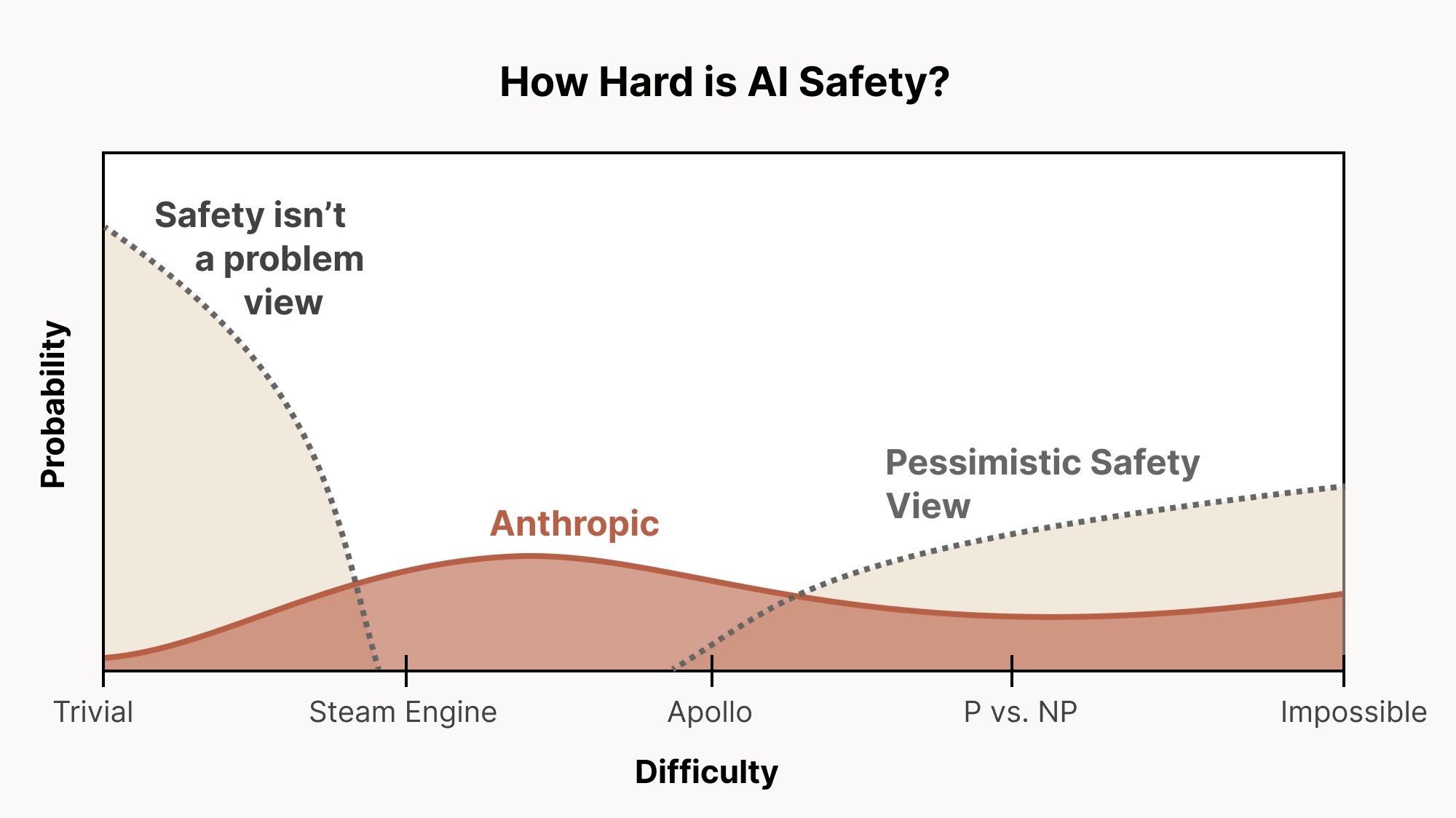
Evan Hubinger, an alignment team lead at Anthropic, says:
If the only thing that we have to do to solve alignment is train away easily detectable behavioral issues…then we are very much in the trivial/steam engine world. We could still fail, even in that world—and it’d be particularly embarrassing to fail that way; we should definitely make sure we don’t—but I think we’re very much up to that challenge and I don’t expect us to fail there.
I disagree; if governments and AI developers don’t start taking extinction risk more seriously, then we are not up to the challenge.

Thomas Savery patented the first commercial steam pump in 1698.1 The device used fire to heat up a boiler full of steam, which would then be cooled to create a partial vacuum and draw water out of a well. Savery’s pump had various problems, and eventually Savery gave up on trying to improve it. Future inventors improved upon the design to make it practical.

It was not until 1769 that Nicolas-Joseph Cugnot developed the first steam-powered vehicle, something that we would recognize as a steam engine in the modern sense.2 The engine took Cugnot four years to develop. Unfortunately, Cugnot neglected to include brakes—a problem that had not arisen in any previous steam-powered devices—and at one point he allegedly crashed his vehicle into a wall.3
Imagine it’s 1765, and you’re tasked with building a steam-powered vehicle. You can build off the work of your predecessors who built steam-powered water pumps and other simpler contraptions; but if you build your engine incorrectly, you die. (Why do you die? I don’t know, but for the sake of the analogy let’s just say that you do.) You’ve never heard of brakes or steering or anything else that automotives come with nowadays. Do you think you can get it all right on the first try?
With a steam engine screwup, the machine breaks. Worst case scenario, the driver dies. ASI has higher stakes. If AI developers make a misstep at the end—for example, the metaphorical equivalent of forgetting to include brakes—everyone dies.
Here’s one way the future might go if aligning AI is only as hard as building the steam engine:
The leading AI developer builds an AI that’s not quite powerful enough to kill everyone, but it’s getting close. They successfully align it: they figure out how to detect alignment faking, they identify how it’s misaligned, and they find ways to fix it. Having satisfied themselves that the current AI is aligned, they scale up to superintelligence.
The alignment techniques that worked on the last model fail on the new one, for reasons that would be fixable if they tinkered with the new model a bit. But the developers don’t get a chance to tinker with it. Instead what happens is that the ASI is smart enough to sneak through the evaluations that caught the previous model’s misalignment. The developer deploys the model—let’s assume they’re being cautious and they initially only deploy the model in a sandbox environment. The environment has strong security, but the ASI—being smarter than all human cybersecurity experts—finds a vulnerability and breaks out; or perhaps it uses superhuman persuasion to convince humans to let it out; or perhaps it continues to fake alignment for long enough that humans sign it off as “aligned” and fully roll it out.
Having made it out of the sandbox, the ASI proceeds to kill everyone.
I don’t have a strong opinion on how exactly this would play out. But if an AI is much smarter than you, and if your alignment techniques don’t fully generalize (and you can’t know that they will), then you might not get a chance to fix “alignment bugs” before you lose control of the AI.
Here’s another way we could die even if alignment is relatively easy:
The leading AI developer knows how to build and align superintelligence, but alignment takes time. Out of fear that a competitor beats them, or out of the CEO being a sociopath who wants more power4, they rush to superintelligence before doing the relatively easy work of solving alignment; then the ASI kills everyone.
The latter scenario would be mitigated by a sufficiently safety-conscious AI developer building the first ASI, but none of the frontier AI companies have credibly demonstrated that they would do the right thing when the time came.
(Of course, that still requires alignment to be easy. If alignment is hard, then we die even if a safety-conscious developer gets to ASI first.)
What if you use the aligned human-level AI to figure out how to align the ASI?
Every AI company’s alignment plan hinges on using AI to solve alignment, a.k.a. alignment bootstrapping. Much of my concern with this approach comes from the fact that we don’t know how hard it is to solve alignment. If we stipulate that alignment is easy, then I’m less concerned. But my level of concern doesn’t go to zero, either.
Recently, I criticized alignment bootstrapping on the basis that:
- it’s a plan to solve a problem of unknown difficulty…
- …using methods that have never been tried before…
- …and if it fails, we all die.
If we stipulate that the alignment problem is easy, then that eliminates concern #1. But that still leaves #2 and #3. We don’t know how well it will work to use AI to solve AI alignment—we don’t know what properties the “alignment assistant” AI will have. We don’t even know how to tell whether what we’re doing is working; and the more work we offload to AI, the harder it is to tell.
What if alignment techniques on weaker AIs generalize to superintelligence?
Then I suppose, by stipulation, we won’t die. But this scenario is not likely.
The basic reason not to expect generalization is that you can’t predict what properties ASI will have. If it can out-think you, then almost by definition, you can’t understand how it will think.
But maybe we get lucky, and we can develop alignment techniques in advance and apply them to an ASI and the techniques will work. Given the current level of seriousness with which AI developers take the alignment problem, we’d better pray that alignment techniques generalize to superintelligence.
If alignment is easy and alignment generalizes, we’re probably okay.5 If alignment is easy but doesn’t generalize, there’s a big risk that we die. More likely than either of those two scenarios is that alignment is hard. However, even if alignment is easy, there are still obvious ways we could fumble the ball and die, and I’m scared that that’s what’s going to happen.
Notes
-
History of the steam engine. Wikipedia. Accessed 2025-12-22. ↩
-
Nicolas-Joseph Cugnot. Wikipedia. Accessed 2025-12-22. ↩
-
Dellis, N. 1769 Cugnot Steam Tractor. Accessed 2025-12-22. ↩
-
This is an accurate description of at least two of the five CEOs of leading AI companies, and possibly all five. ↩
-
My off-the-cuff estimate is a 10% chance of misalignment-driven extinction in that scenario—still ludicrously high, but much lower than my unconditional probability. ↩