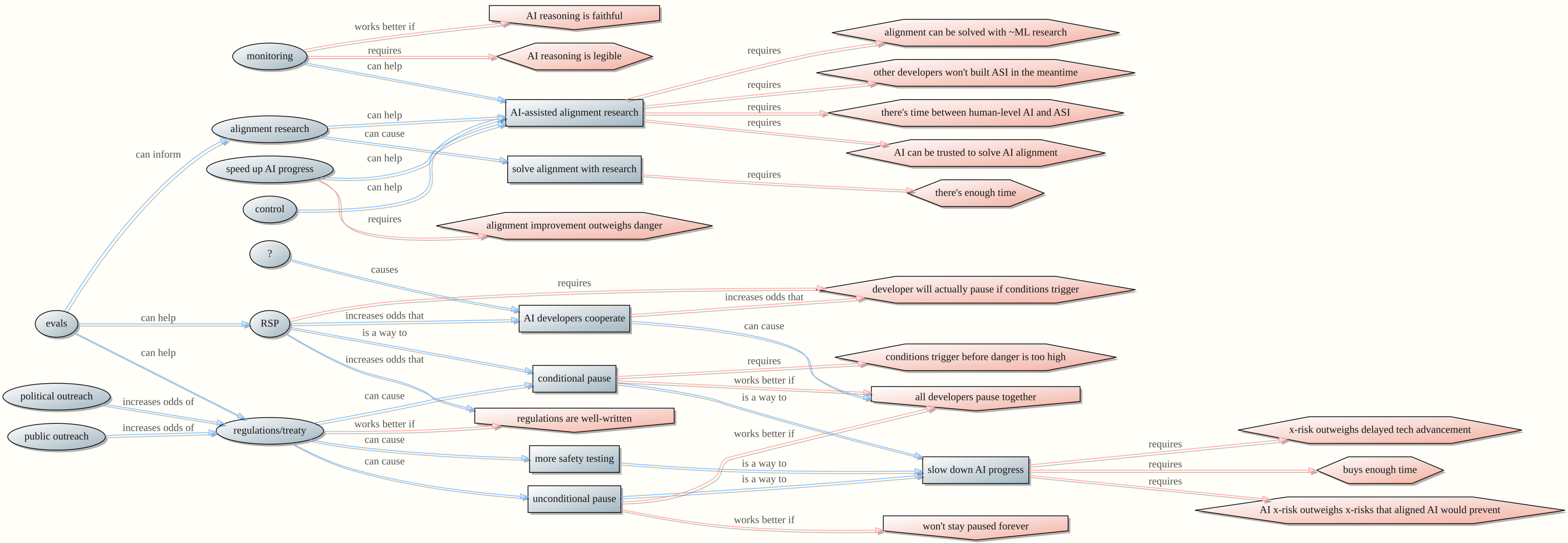
An argument goes: If we don’t build aligned artificial superintelligence, we risk driving ourselves extinct for some other reason. We should rush to build ASI quickly, in spite of the risks—the longer we wait, the more vulnerable we are to extinction from a different cause.
Other than ASI, the biggest extinction risk is synthetic biology. Some lab could (accidentally or on purpose) develop a highly transmissible, 100% fatal super-plague that wipes out humanity.
An aligned ASI could stop that from happening by shutting down dangerous biological research, or by developing advanced countermeasures that stop the spread of deadly infections. So the argument goes: We need to build ASI to save us from non-AI extinction risks.
However, that argument doesn’t work. In the near term, AI will make biological risks worse, not better. AI will accelerate scientific research, which will bring us closer to the level of knowledge necessary to build extinction-level pathogens. And in the long term, the way ASI eliminates biological x-risk is by taking control of the world.
Continue reading






{kind=link}